Update (Feb142016): see bottom for an improved strategy.
The Game
At a December workshop, I played The Resistance, a game in which there are two teams, the resistance and the spies. The spies know everyone’s identity; each resistance player knows only one’s own. Overall, the goal of the spies is to remain undetected; the goal of the resistance is to discover who the spies are.
Play proceeds in rounds in which a player nominates a subgroup to go on a “mission”. The nomination is then voted on. If the vote succeeds, every member of a mission plays either a “success” or “failure” card for the mission. One or two failure cards (depending on the mission size) causes the mission to fail. The cards played in a mission are public, but it is secret who played which card. (If the vote fails, the next player nominates a subgroup.)
The spies’ goal is to fail missions without being detected, and the resistance goal is to have missions succeed. So the spies generally wish to play failure cards while in a mission. Furthermore, spies always want some spy in the mission to spoil it. The resistance wants no spies to go on missions. The problem for the resistance is that when a mission fails, they know one or more of the subgroup is a spy, they just don’t know which one.
The spies win the game if they can cause three missions to fail before the resistance can cause three missions to succeed.
The game is simple but engaging, and similar in spirit to the game Mafia (Werewolf).y
The Problem
I played the game with computer scientists from the top universities and research labs. We debated strategy and were generally pretty bad at the game, despite having a lot of fun. In particular, the spies seemed to win a lot.
The problem is: what is the optimal approach to game play?
The Approach
The problem is a great fit for Bayesian Analysis. In each round, we learn partial information about the players from the group outcome. Only spies play failure cards. We can use that information to update our believe in the probability that a player is a spy.
Suppose there are four players, ![[ a, b, c, d]](https://s0.wp.com/latex.php?latex=%5B+a%2C+b%2C+c%2C+d%5D&bg=ffffff&fg=333333&s=0&c=20201002)

![[ a, b, c ]](https://s0.wp.com/latex.php?latex=%5B+a%2C+b%2C+c+%5D&bg=ffffff&fg=333333&s=0&c=20201002)

Bayes Theorem states that
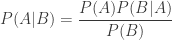
In our case, “A” is the event that a particular player is a spy, and “B” is the event that we we observed a particular set of mission cards. We wish to compute 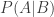
So for each mission, we apply Bayes’ Theorem to each player, including the players not in the mission—if the spy probabilities increase (or decrease) for the mission players, then they decrease (or increase) for the non-mission players.
From the cards 


- spies
- spies
- spies
![= [a, b]](https://s0.wp.com/latex.php?latex=%3D+%5Ba%2C+b%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![= [a, c]](https://s0.wp.com/latex.php?latex=%3D+%5Ba%2C+c%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![= [b, c]](https://s0.wp.com/latex.php?latex=%3D+%5Bb%2C+c%5D&bg=ffffff&fg=333333&s=0&c=20201002)
For each combination, we multiply the probabilities for the assignments. So in case (1), we have

for assigning players 

So 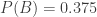
To compute P(B|A), we assume that player a is a spy, and now recompute the probability that ![[b, c]](https://s0.wp.com/latex.php?latex=%5Bb%2C+c%5D&bg=ffffff&fg=333333&s=0&c=20201002)


So player’s a probability of being a spy shot up to 0.66, and so did player b’s and c’s.
Player
The Strategies
How should the game be played by the resistance and spies, respectively, to increase the odds of winning?
For the resistance, picking the players the least likely to be spies is optimal. Let’s call this the pick-lowest strategy.
One possible optimization is to always pick yourself in a mission. The rational is that you know if you are part of the resistance, and you pick yourself for a mission, then you have at least one guaranteed non-spy. So even if your probability of being a spy as known to the group is higher than others, you have perfect knowledge of yourself. Let’s call this the pick-myself strategy,
For the spies, there are a few options. By default, the spies could always play a failure card (fail-always). But a spy might also play a success card to avoid detection; doing so is especially advantageous in the early rounds; one strategy is to never fail the first round (succeed-first). If the spies can collude to ensure only one plays a failure card during a mission, that provides the least amount of information to the resistance (fail-one).
There are other strategies and other combinations of strategies, but this is a good representative sample.
Which are the best strategies?
Findings
To discover the best strategies, we use Monte-Carlo simulations on the strategies over each number of players (with different number of players, there are different number of spies and missions). I found a few interesting results:
- The best chance of wining for the resistance, and the closest odds between the resistance and spies, is with six players. At six players, the resistance has a 30-40% chance of winning under different strategies. The worst configuration is eight players, with not more than a 14% chance of winning for the resistance. During actual game play, it seemed that the odds favored the spies.
- The best strategy for the resistance is the pick-lowest strategy. The strategy may be counter-intuitive, but consider this: the pick-myself strategy provides the spies an opportunity to always include themselves in a mission when picking a mission. The pick-myself strategy is an instance of a local maxima (i.e., local knowledge of knowing yourself to be part of the resistance) that is non-optimal.
- Moreover, voting becomes a no-op. The game includes a voting round in which players vote on the proposed players for a mission. But If the resistance agrees on an optimal strategy, any deviation from the strategy by a player is because the player is a spy. If the person does deviation, the resistance votes against it (and resistance outnumber spies, so will win the vote), and we now have complete assurance the proposer is a spy. The spies have no choice but to follow the optimal strategy of the resistance.
- Of the spy strategies listed above, the best is the fail-one strategy, which is intuitive. The succeed-first strategy is another example of a local maxima that is non-optimal; while it protects that particular spy from detection, it is more valuable for the spies in general to fail the mission.
The related Mafia game has some analytical results, giving bounds on (their version of) the resistance to spies. I have not done that, nor have I done Monte-Carlo analysis to determine what proportion of resistance and spies and mission sizes gives a more even chance of winning. In Mafia, it is noted that in actual game play, the resistance wins more often than simulations/analytical analysis would suggest, with different attributions (e.g., people are bad at lying over iterative rounds).
Play Along at Home
I have implemented the Bayesian solver in a webserver hosted on Amazon Web Services. You can use the solver when playing with others.
http://ec2-54-173-249-238.compute-1.amazonaws.com/
An easier-to-remember link is http://tiny.cc/theresistance1.
If you want to run Monte Carlo simulations, you will have to download the code and run it locally, however.
Implementation
https://github.com/leepike/theresistance
Update (Feb142016)
It has been pointed out by Eike Schulte in the comments and Iavor Diatchki that by including some additional information, the strategy might be improved. This is indeed the case. The intuition is that if a group has previously included a spy, that group should not be selected again, even if it is the lowest probability group. For example, with five players, consider the following rounds:
- Round 0: players [0,1] are selected and there is one fail card.
- Round 1: players [2,3,4] are selected and there is one fail card.
- Round 2: players [2,3] are selected and there are no fail cards.
At this point, players [0,1] have a 0.5 probability of being a spy and players [2,3,4] have a 1/3 probability. So in round 3, we do not want to select players [2,3,4] even if they have the lowest probabilities. So we select a group with the lowest spy probability that has not already included a spy. The server has been updated to include this strategy. The strategy does better; for example, at 6 players, we have just over a 50% chance of winning!




, an SD card for logging data, air pressure sensor, and voltage regulator.")







